

The one-armed bandit model is a well-known statistical model in machine learning, but is often (too) little used in marketing.
Introduction to the one-armed bandit model and its use in marketing
Learn how to leverage the one-armed bandit theory, a reinforcement learning model, in different areas of marketing.
What is a one-armed bandit?
It is a statistical learning model, with the aim to make a sequential choice between several actions based on the rewards they generate.
An example of the application (which gave its name to the model) is the choice between several slot machines, “slot machine” being also called “one-armed bandit” in English. The context is as follows: a player has a choice of several slot machines (also called arms) whose average profitability is not known in advance. It is this ignorance of profitability that makes it a learning problem. The player has a certain budget, for example N coins of 1 dollar, and has to play these coins one by one on the different slot machines. The goal is to collect as much money as possible after N draws. The reward given by the chosen slot machine is a random variable drawn from a certain probability law.
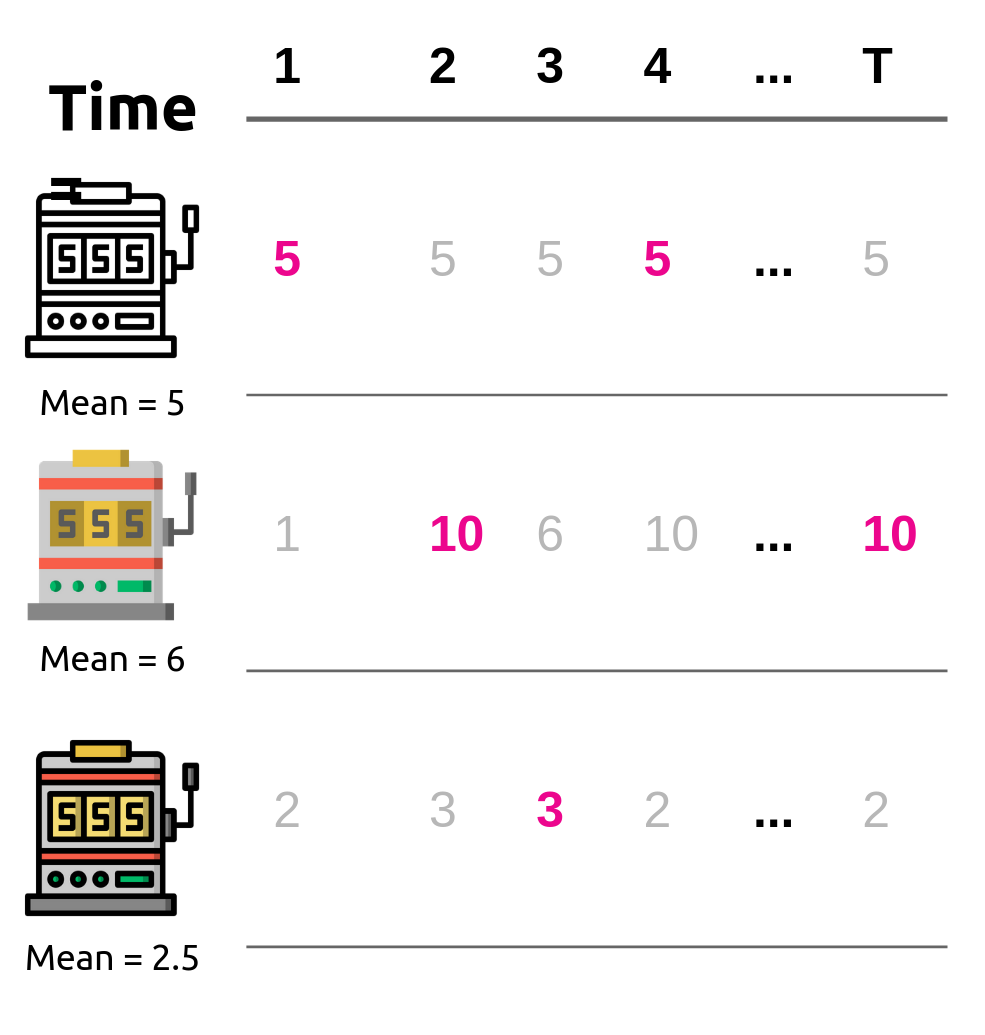
One can consider that in each round rewards are drawn from the slot machines that were not chosen, but are neither observed nor collected by the player, see the figure below, where the observed rewards are shown in color.
In this example, the player will have to allocate a certain amount of money to find the most profitable slots (this is called exploration) and the rest of the budget to invest in these slots (this is called exploitation). The problem of the one-armed bandits thus comes down to solving an exploration/exploitation trade-off that consists in choosing when to exploit and when to explore.
What are the possible applications in marketing?
The one-armed bandit model is extremely versatile, since it can be applied whenever there is a sequential choice between several actions, and one can rely on the observation of rewards to make an informed choice.
Content selection / Recommendation
The choice of a slot machine in the above example can be replaced by any type of reward action. We can therefore imagine that we have the choice between several contents/banners to propose to a user each time he connects to a site, and that we are rewarded by a click (or another KPI to be defined) as soon as the user is satisfied by the proposal. Assuming that the previous content does not influence the user’s reaction, this use case is a direct application of the one-armed bandit theory. This example can of course also be extended to the sending of emails or product recommendations.
Search for the best email /content / landing page or the best banner
So far we have only talked about the “classic” version of one-armed bandits, where the objective is to maximize the accumulated reward. An alternative goal is to learn what the best action is, or what actions are better than a certain baseline. These models are gathered under the name of pure exploration bandits (exploitation is indeed no longer necessary in this context). They solve a problem similarly to A/B testing, which consists of finding the most effective treatment out of several. It requires dividing the population in advance into two sub-populations: the one that will receive treatment A, and the one that will receive treatment B.
Conversely, a one-armed bandit algorithm will sequentially assign the individuals it is to treat to treatment A or B based on the rewards it has observed on the previous individuals. This allows either to find the best one faster with a given percentage of errors, or to reach a more significant result in the same time. This context is suitable for example if you want to test several versions of an email or a banner before choosing the version to send to the majority of the population. This model is also particularly relevant for testing different landing pages. Eventually, we could also choose more complicated treatments, such as mail + banner versus mail + SMS …
Real-time bidding (RTB)
The choice of bid for an RTB campaign can also be formulated as a one-armed bandit problem. The actions are then the bids (which can be, depending on the choice of model, discrete or continuous) and the reward is the click or the purchase.
Conclusion
The one-armed bandits are a statistical model that models the sequential choice between several actions generating different rewards. It can be used in marketing for a wide variety of purposes, from content selection to bid selection in RTB. At Numberly, we’re looking into this last topic carefully. The application of one-armed bandits to bid selection is developed in this article, which we encourage you to read if you want to know more.